AI-Era Delivery: The Terms Reshaping Modern Teams
Part 3 of 3. Exploring how AI introduces new vocabulary and new translation challenges across modern delivery teams.
The New Translation Layer
Part 1 explored how strategic and requirements terms shift meaning across organizational altitudes.
Part 2 examined how that drift continues through process modeling and sprint execution.
This article looks at the next layer of complexity: AI is introducing an entirely new vocabulary into cross-functional delivery.
When business says “add AI,” engineering often hears a long list of unstated decisions. Which model? What retrieval strategy? How are prompts versioned? What quality metrics matter? How is drift monitored?
The translation problem that affected traditional delivery does not disappear with AI. It often reappears in a new form, expressed through new terms.
Phase 5: 2026 Modern Implementation Trends
RAG (Retrieval-Augmented Generation)
What it means:
An AI architecture pattern that grounds LLM responses in retrieved documents rather than relying solely on training data. Relevant context is retrieved first, then used to generate responses.
Why it exists:
It reduces hallucinations, keeps responses aligned with current information, and allows outputs to reference specific sources without retraining the model.
How it translates to tech:
RAG is commonly used in enterprise AI to avoid confident but incorrect answers. Instead of answering from general knowledge, the system searches internal documents, policies, or databases and injects relevant excerpts into the prompt.
Real scenario: Legal teams want an AI assistant to answer compliance questions.
Direct LLM approach (no RAG):
User Query: "What's our data retention policy for customer emails?"
Prompt to LLM:
"Answer the user's question about data retention policies."
Risk: AI generates generic best practices or outdated regulatory info,
not your company's actual policy.
RAG-based approach:
User Query: "What's our data retention policy for customer emails?"
Step 1 - Retrieval:
System searches internal policy database
Finds: "Data Retention Policy v3.2, Section 4.7: Customer Communication"
Step 2 - Augmented Prompt to LLM:
"You are a compliance assistant. Answer the question using ONLY the
provided policy documents. Cite specific sections in your response.
POLICY DOCUMENT:
[Retrieved text from Data Retention Policy v3.2, Section 4.7]
USER QUESTION: What's our data retention policy for customer emails?
Provide a clear answer with specific policy references."
Output: "According to our Data Retention Policy v3.2, Section 4.7,
customer emails must be retained for 7 years from the date of final
correspondence to comply with regulatory requirements..."
The difference is accuracy and auditability.
Common failure: AI features are deployed without retrieval, effectively outsourcing accuracy to a general-purpose model. Errors surface later as compliance risks or loss of trust.
Translation bridge:
When business asks for “AI chat with our documents,” the technical need is usually RAG: a vector store, an ingestion pipeline, and retrieval-aware prompting. The investment is about accuracy, not novelty.
Prompt Engineering
What it means:
The practice of designing, testing, and refining prompts to produce reliable, structured, and appropriate outputs from AI systems.
Why it exists:
LLMs are highly sensitive to input phrasing. Small changes can significantly alter tone, structure, accuracy, or safety.
How it translates to tech:
Prompts function as behavior specifications. For AI features, prompt quality plays a role similar to test coverage or validation logic in traditional systems.
Real scenario: Product asks for “AI-written professional emails.”
Naive prompt (what fails in production):
Write a professional email.
Result: Wildly inconsistent outputs - sometimes overly formal, sometimes too casual, variable length, inconsistent structure, occasional inappropriate tone.
Engineered prompt (production-ready):
You are a professional business email assistant for [Company Name].
Your role is to draft clear, concise, and professionally appropriate emails.
TASK: Write a professional email for the following scenario.
STYLE REQUIREMENTS:
- Tone: Professional but approachable (not overly formal or casual)
- Length: 3-5 sentences maximum
- Structure: Greeting → Purpose → Action/Next Step → Closing
- Voice: First person, active voice
- Formality level: Business casual
MANDATORY ELEMENTS:
1. Subject line (max 8 words, specific and actionable)
2. Personalized greeting using recipient's first name
3. Clear purpose statement in opening sentence
4. Specific next step or timeline in closing
5. Professional signature
PROHIBITED:
- Humor, jokes, or casual expressions
- Apologies unless directly relevant to the situation
- Passive or overly deferential language ("just wondering if maybe...")
- Marketing language or sales pressure
- Excessive politeness markers ("I hope this email finds you well")
OUTPUT FORMAT:
Subject: [subject line]
Hi [Name],
[Email body: 3-5 sentences]
Best regards,
[Sender Name]
EXAMPLES:
Example 1 - Meeting Request:
Subject: Q2 Planning Discussion - 30 Min
Hi Sarah,
I'd like to discuss our Q2 marketing strategy and align on budget
priorities. Could we schedule 30 minutes this week? I have availability
Tuesday 2-4pm or Thursday morning.
Best regards,
Alex
Example 2 - Project Update:
Subject: Design Review Complete - Action Items
Hi Marcus,
I've completed the design review for the customer portal. Three items
need your input before we proceed to development. I've flagged them in
the attached document—can you review by Friday?
Best regards,
Jamie
---
Now write an email for this scenario:
[Insert specific scenario details]
Output quality: Consistent, appropriate, reliable within defined bounds.
Why this matters:
AI features often fail not because models are weak, but because prompts are under-specified. Inconsistent quality erodes user trust quickly.
Common failure: Teams assume inconsistency is inherent to AI. In practice, poorly engineered prompts are usually the cause.
Example: Customer Support Response Generation
Poor prompt:
Write a helpful customer support response.
Problems: No tone guidance, no length constraints, no brand voice alignment, no handling of edge cases.
Engineered prompt:
You are [Company Name]'s customer support AI assistant.
ROLE: Provide helpful, empathetic, and solution-focused responses.
CONSTRAINTS:
- Maximum 4 sentences
- Use customer's name once
- Acknowledge issue specifically
- Provide concrete next step
- Never promise what can't be delivered
TONE CALIBRATION:
- Empathetic but not overly apologetic
- Solution-focused, not defensive
- Professional but warm
- Clear and direct
RESPONSE STRUCTURE:
1. Acknowledge specific issue
2. Explain resolution or next step
3. Provide timeline or action item
4. Offer additional support if needed
EXAMPLE - Shipping Delay:
"Hi Jordan, I understand your order hasn't arrived as expected. I've
checked your tracking and it's currently in transit with a revised
delivery date of Thursday. I'll send you an email as soon as it's out
for delivery. Is there anything else I can help with?"
Now respond to: [Customer message]
Translation bridge:
Treat prompts as critical application code:
- Version them (Git repository)
- Test them systematically (evaluation sets)
- Document expected behavior
- Review changes formally (like code reviews)
- Monitor production performance
- Roll back problematic versions
Prompt engineering is less about creativity and more about disciplined system design.
LLMOps
What it means:
Operational practices for running AI systems in production. This includes monitoring output quality, managing prompt versions, tracking costs, and detecting performance drift.
Why it exists:
AI systems behave differently from traditional software. Outputs are probabilistic, costs vary per request, and failures are often subtle rather than binary.
How it translates to tech:
LLMOps provides the guardrails that make AI usable at scale.
Real scenario: An AI-powered support feature performs well initially, then degrades weeks later.
Possible causes include model updates by the provider, changes in user behavior, or feedback loops reinforcing edge cases. Without monitoring, teams discover issues only through complaints.
With LLMOps: Quality degradation is detected early, prompt versions can be rolled back, cost spikes are visible, and changes are traceable.
Example: Monitoring Setup
# LLMOps Configuration Example
quality_monitoring:
evaluation_frequency: "hourly"
sample_size: 100
metrics:
- accuracy_score
- hallucination_rate
- response_relevance
- citation_accuracy
thresholds:
accuracy_minimum: 0.85
hallucination_maximum: 0.05
alert_channels:
- slack: "#ai-monitoring"
- email: "ai-ops@company.com"
cost_monitoring:
budget_daily: 500.00
budget_monthly: 12000.00
alert_threshold: 0.85
track_by:
- endpoint
- user_segment
- prompt_version
prompt_versioning:
repository: "git@github.com:company/ai-prompts"
environments:
- dev
- staging
- production
approval_required: true
rollback_enabled: true
drift_detection:
baseline_period: "7_days"
comparison_window: "24_hours"
metrics:
- response_length_distribution
- sentiment_distribution
- topic_distribution
alert_on_deviation: 0.15
Translation bridge:
AI success metrics differ from traditional ones. Traditional systems focus on uptime and error rates. AI systems also require visibility into quality, consistency, hallucination rates, and cost per interaction.
Vector Databases
What it means:
Databases optimized for storing and searching embeddings, enabling semantic similarity rather than exact keyword matching.
Why it exists:
Traditional databases are excellent for structured queries but ineffective at finding “related meaning.” Vector databases make semantic search and RAG possible at scale.
How it translates to tech:
When users say they want “search that understands intent,” they are usually describing semantic search backed by embeddings.
Real scenario: Searching for “setting up direct deposit” returns results related to payroll configuration, banking setup, and onboarding despite different wording.
Traditional keyword search:
SELECT * FROM documents
WHERE content LIKE '%direct deposit%';
-- Returns: 3 documents with exact phrase "direct deposit"
-- Misses: 20+ relevant documents using different terminology
Vector database semantic search:
# User query
query = "setting up direct deposit"
# Convert to embedding
query_embedding = embed_model.encode(query)
# Search vector database
results = vector_db.similarity_search(
query_vector=query_embedding,
limit=10,
similarity_threshold=0.7
)
# Returns documents semantically related:
# - "Payroll Configuration Guide"
# - "Bank Account Registration"
# - "Employee Payment Methods"
# - "New Hire Onboarding Checklist"
# - "Benefits Enrollment: Direct Deposit Section"
Common failure: Teams improve keyword search instead of addressing the vocabulary mismatch between users and content.
Translation bridge:
Vector search is mathematical, not magical. It enables similarity-based retrieval, but it is not appropriate for every use case. Exact queries and compliance-heavy workflows still favor traditional databases.
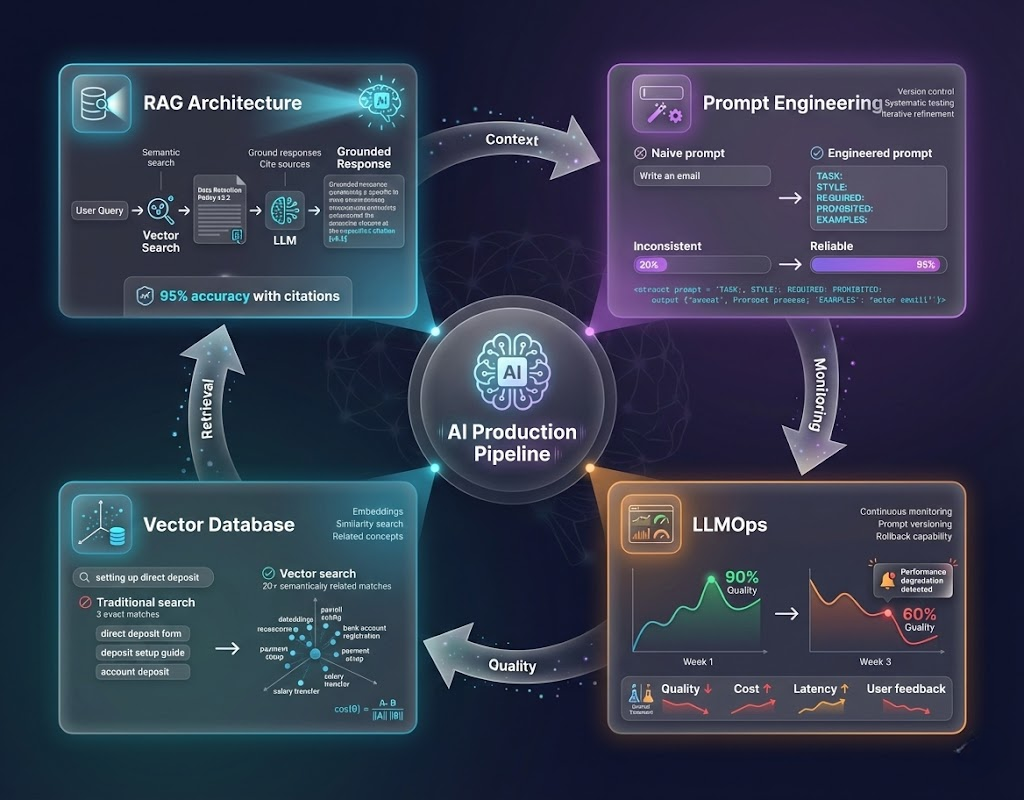 RAG, Prompt Engineering, LLMOps, and Vector Databases working together across the AI delivery lifecycle
RAG, Prompt Engineering, LLMOps, and Vector Databases working together across the AI delivery lifecycle
The AI Translation Challenge
AI adds a new layer of ambiguity to delivery conversations.
Business often asks for outcomes. Engineering hears architectural choices, quality tradeoffs, and operational constraints. The gap is familiar. The vocabulary is new. The risk is higher.
Traditional software fails visibly. AI can fail confidently and invisibly.
Making AI Translation Work
1. Define success before building
Don’t accept “AI-powered” as a specification. Require measurable targets:
❌ Vague: "Add AI to customer support"
✅ Specific:
- AI handles tier-1 questions with 90% accuracy
- AI responses cite sources with <5% hallucination rate
- 95% of AI responses require no human editing
- Average response time under 3 seconds
- Cost per interaction under $0.02
- User satisfaction score above 4.2/5.0
2. Plan for prompt engineering effort
Prompt design and testing often take 30-40% of AI feature development time. Budget accordingly.
3. Implement LLMOps early
Monitoring quality and drift is easier to build before launch than after trust erodes.
4. Use RAG intentionally
In many enterprise contexts, grounding responses in retrieved data significantly reduces risk.
5. Treat vector search as infrastructure
Embeddings, indexing, and retrieval pipelines are foundational components, not afterthoughts.
Practical Example: Complete AI Feature Specification
Business Request: “We need AI to help employees find HR policies faster.”
Translation to Technical Requirements:
Feature: AI-Powered HR Policy Assistant
SUCCESS METRICS:
- Query resolution rate: 85% (no escalation needed)
- Response accuracy: 90% (verified against source policies)
- Citation accuracy: 95% (correct policy references)
- User satisfaction: 4.0+/5.0
- Average response time: <4 seconds
- Cost per query: <$0.03
ARCHITECTURE:
- RAG-based (retrieves from policy database before generating)
- Vector database: Pinecone or Weaviate
- Embedding model: text-embedding-ada-002
- LLM: Claude Sonnet 3.5 or GPT-4
- Prompt versioning: Git repository
PROMPT TEMPLATE:
[Structured prompt with constraints, examples, citation requirements]
MONITORING (LLMOps):
- Quality checks: Sample 50 responses daily
- Cost tracking: Alert if daily spend exceeds $100
- Drift detection: Compare response patterns weekly
- A/B testing: New prompt versions tested on 10% traffic
SAFETY RAILS:
- Confidence scoring: Flag responses below 0.7 confidence
- Human review: Escalate sensitive topics (termination, legal)
- Fallback: "I don't have enough information" for low-confidence queries
ROLLOUT PLAN:
- Week 1-2: Internal pilot (50 employees)
- Week 3-4: Department rollout (500 employees)
- Week 5+: Company-wide (5,000 employees)
- Continuous: Monitor, tune prompts, adjust thresholds
This level of specification prevents translation failures.
The Complete Translation Picture
Across three articles, terminology shifted across five delivery phases:
- Phase 1: Strategic Planning (Business case, roadmap, POC)
- Phase 2: Requirements (BRD, FRD, user stories, acceptance criteria)
- Phase 3: Process Design (BPMN, wireframes)
- Phase 4: Execution (Sprint backlog, DoD, technical debt)
- Phase 5: Modern AI Trends (RAG, prompts, LLMOps, vectors)
The pattern stays consistent: the same words carry different meanings at different altitudes.
Alignment improves when teams name the artifact, clarify the frame, and make assumptions explicit.
The Skill That Matters
Technical skills are learnable. Domain knowledge is transferable.
The differentiator is translation fluency.
Knowing which language is being spoken, and when agreement is only superficial.
Not translating words, but translating intent into outcomes.
Putting It Into Practice
If you’re an engineer:
- Treat prompts as code: version, test, review, monitor
- Budget 30-40% of AI feature time for prompt engineering
- Implement quality monitoring before production launch
If you’re in product:
- Define AI success metrics upfront (not “AI-powered”)
- Plan for iterative prompt tuning post-launch
- Budget for ongoing LLMOps infrastructure
If you’re in leadership:
- Recognize prompt engineering as a discipline requiring time and skill
- Fund LLMOps infrastructure from day one
- Expect AI features to require continuous tuning, not “deploy and forget”
If you’re building AI features:
- Default to RAG for enterprise use cases
- Version control prompts like application code
- Monitor quality metrics continuously, not just availability
The Bottom Line
Cross-functional delivery struggles not because teams lack expertise, but because context is rarely named.
Business speaks in outcomes. Product speaks in capabilities. Engineering speaks in implementations. AI engineers speak in prompts, embeddings, and retrieval strategies.
We call it all “requirements” and wonder why alignment breaks.
The solution is explicit translation.
Name the artifact. Clarify the context. Acknowledge the perspective. Make assumptions visible. Budget for translation as first-class work.
Not to eliminate ambiguity—some is inevitable and useful.
But to make ambiguity explicit, so teams can navigate it together.
That’s how cross-functional teams stop talking past each other and start building the right things.
Not because everyone speaks the same language.
Because everyone knows which language is being spoken.
Complete series:
→ Part 1: When words drift
→ Part 2: From Blueprints to Sprints
→ Part 3: AI-Era Delivery Terms (you are here)
Working on AI-enabled delivery or cross-functional teams? Let’s discuss what translation looks like in your context.